What is technical content marketing?
- A frontend developer needs help choosing between React Server Components and Astro Islands.
- A senior SRE needs help understanding whether a new observability tool’s p99 claims are true.
- A DevOps engineer needs help wiring up a CI/CD pipeline that deploys to both EKS and legacy infra.
- A CTO needs help making the build-vs-buy case for real-time messaging.
- A non-technical founder needs help understanding their product’s current auth setup.
- An AI agent needs help selecting the right API for a task its meatboy is vibe-coding.
- A Hacker News commenter needs help arguing.1
Technical content marketing is all this and more. It is your docs and your tutorials, your guides and your explainers, your benchmarks and your thought leadership. If you are a devtool or are API-first or AI-native or data-led, technical content marketing is the technical understanding of your topic you share with your audience that help them and shows them your expertise.
Technical content marketing is how you win users through clarity, depth, and trust. It is a marketing channel built on knowledge and for the knowledgable.
What technical content counts as technical content marketing?
All of it.
There is nuance to this, but that’s the gist. Everything is marketing.
The best exemplar of this is Stripe. What is the one thing Stripe is known for in the developer community? It’s docs. The clarity of Stripe documentation is a marketing tool for the company. Stripe docs treat the developer as the primary user of the company, not a downstream implementer of someone else’s decision. It gives developers what they need: real code, runnable against live test data, and every concept is explained once, clearly. Stripe know all this means a lot to developers.
At the other end of the spectrum you have Stripe Press. Also technical content marketing. The books explain technical concepts clearly, just bound on beautiful leather instead of pixelated on a screen. But again, they give developers what they want—a clear understanding of a complex topic.2
And everything in between. A blog post explaining a tricky migration is marketing. Great marketing. A conference talk on YouTube is marketing. An architecture deep-dive that gets dissected on Hacker News is marketing. A good error message is marketing. If it teaches a technical reader something they needed to know, it’s doing the work.
Who is the audience for technical content marketing?
Developers.
Developers. Developers. Developers. Developers. Developers. Developers. Developers.

Developers (or engineers or analysts or architects or someone with a technical role) are going to be the audience almost all of the time. This is the struggle with writing good technical content—if you aren’t technically-minded, you can’t write for the audience.
That is not to say all technical content is for nerds. A great piece of technical content marketing could be read by anyone to understand the topic. A great technical explainer on how LLMs work would be useful for a much wider audience than just developers.
This is why we started with enumerating some of the instances of technical content marketing by audience. Who is reading your technical content informs how you produce that technical content.
- A developer trying to get vector search working needs a quickstart with real embeddings and a clear note on which distance metric to pick.
- A CTO deciding between pgvector and a dedicated vector database needs a decision framework grounded in scale, latency, and team expertise.
- An AI engineer trying to understand why their RAG pipeline is returning irrelevant chunks needs a deep explainer on how embedding models and chunking strategies interact.
Same topic, same product, three completely different pieces of content.
What are the types of technical content marketing?
You can slice and dice content how you want, but in this house we believe Diataxis is the way to go. Diataxis breaks down technical content into four types:

Tutorials are for learning. The reader doesn’t yet know what they don’t know, and they want to be walked through something end-to-end. “Build a chat app with Stream in 30 minutes” is a tutorial. The success criterion is that the reader finishes with a working thing and a sense of how the pieces fit together. The failure mode is skipping steps because they feel obvious to the writer.
How-to guides are for doing. The reader already knows roughly what they need and wants to get it done without learning more theory than necessary. “How to deploy a Next.js app to both Vercel and a self-hosted Docker container” is a how-to. The success criterion is that the reader ships. The failure mode is wandering into explanation when they just wanted the steps.
Explanation is for understanding. The reader wants to know why something works the way it does, or how to think about a trade-off. “Why event-driven architecture breaks down at small team sizes” is explanation. The success criterion is that the reader walks away with a clearer mental model than they had before. The failure mode is neutral-voice hedging when the writer clearly has a point of view. An explainer without a thesis reads as dishonest.
Reference is for looking things up. The reader knows exactly what they need and wants to find it fast. API docs, error code lists, and configuration references all sit here. The success criterion is scannability and completeness. The failure mode is trying to teach the reader something when they just wanted a lookup.
Let’s map these back to the intro. The DevOps engineer wiring up CI/CD needs a how-to. The SRE verifying p99 claims needs explanation backed by a benchmark. The CTO making a build-vs-buy case needs explanation repackaged for a decision-maker. The frontend developer choosing between RSC and Astro Islands needs explanation plus reference. The AI agent needs reference and only reference, structured in a way a machine can actually consume.
What are the building blocks of technical content?
Diátaxis gives you the shape of the piece. The building blocks are what goes inside. These are format-agnostic, but certain combinations cluster naturally with certain quadrants.
The words
This is where almost all technical content goes wrong. They either:
- Forget the words. Instead of describing what is happening, they just leave it as an exercise for the reader. A code sample dropped into the middle of an article without setup, context, or follow-through assumes the reader can reverse-engineer the author’s intent. Some can. Most won’t bother.
- Write the wrong words. This is why Argot exists. Marketers, generally, struggle with using the correct nomenclature for a technical audience. Jargon matters! When developers see technical concepts being used wrong, trust entirely evaporates.
- Use boring words. Any read should be fun or interesting. Yes, sometimes (as with reference), you don’t need excess verbiage, but with tutorials and explainers, taking a reader on a journey is perfectly cromulent.
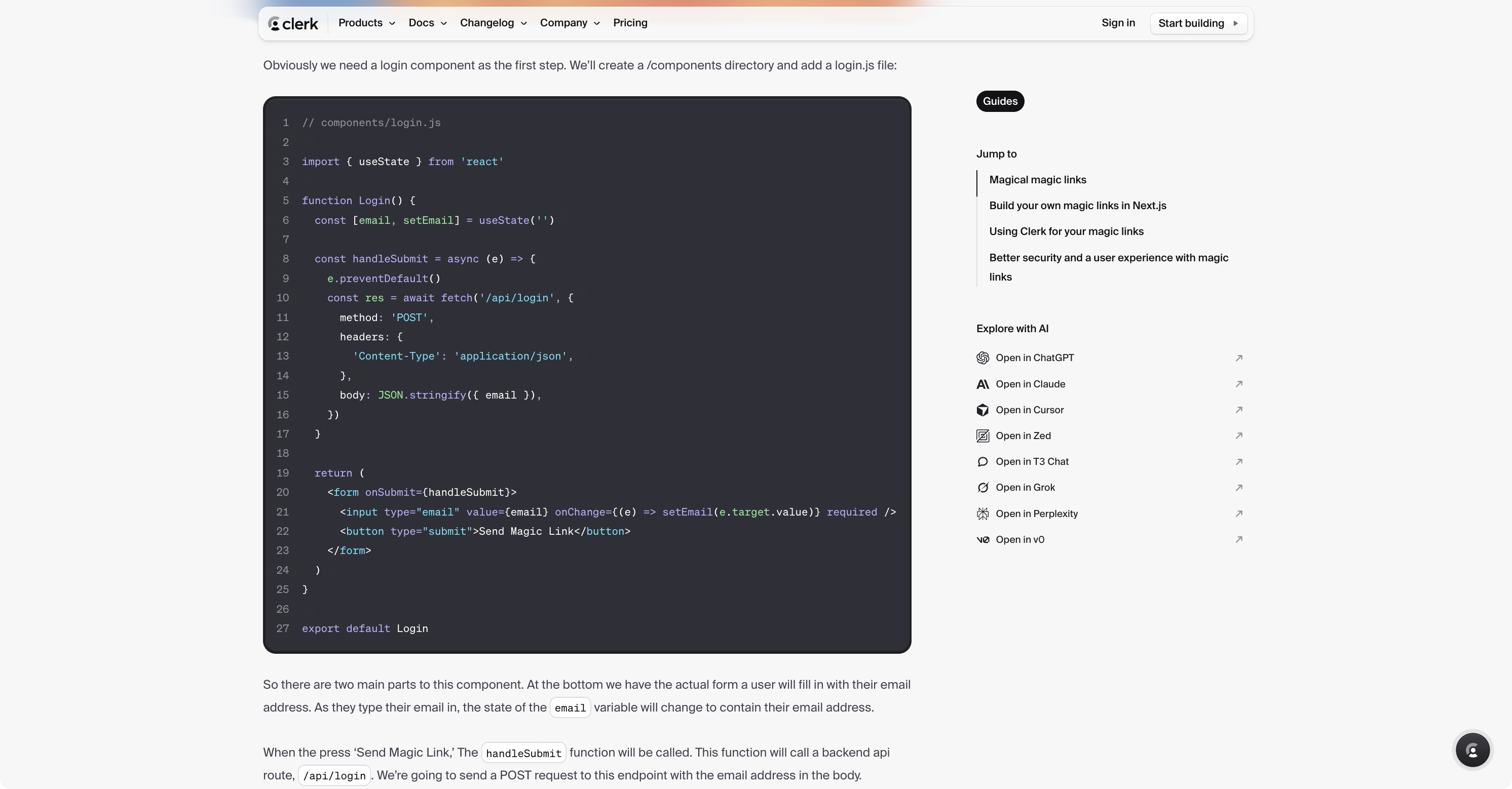
The code
This is the single highest-leverage building block with technical content. A good code sample:
- runs,
- using realistic data,
- and shows one thing clearly.
Code samples should be part of a working whole, not random, orphaned snippets that look good. If you are writing a tutorial or how-to, the reader is learning and doing. Code that doesn’t work takes them entirely away from that.
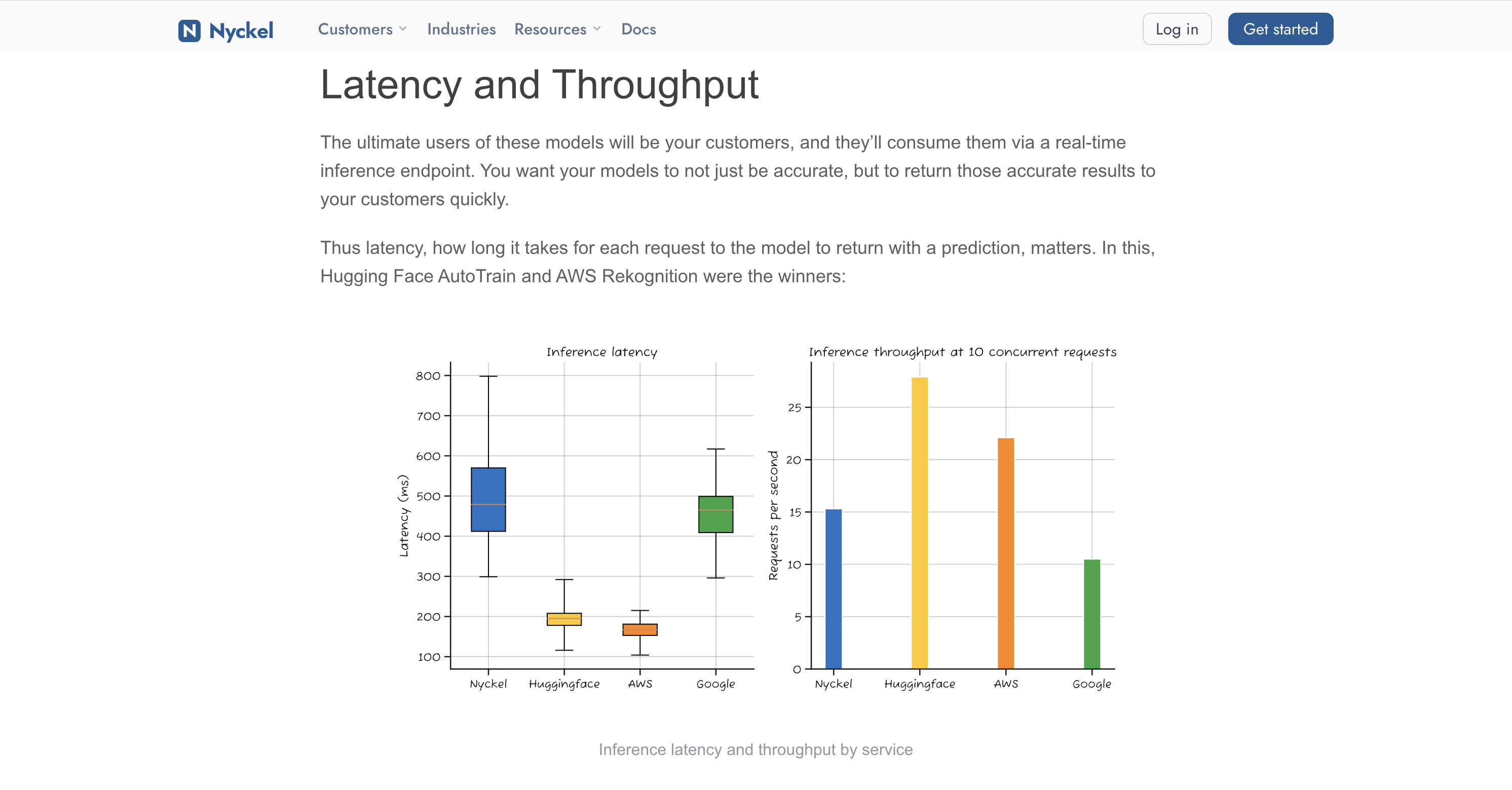
The numbers
What separates a claim from an assertion. A benchmark needs a stated methodology, reproducible setup, and honesty about what it doesn’t measure. “Our system does 100k requests per second” is marketing. “Our system does 100k requests per second on a c7g.4xlarge with this workload, and here’s the harness” is technical content marketing.
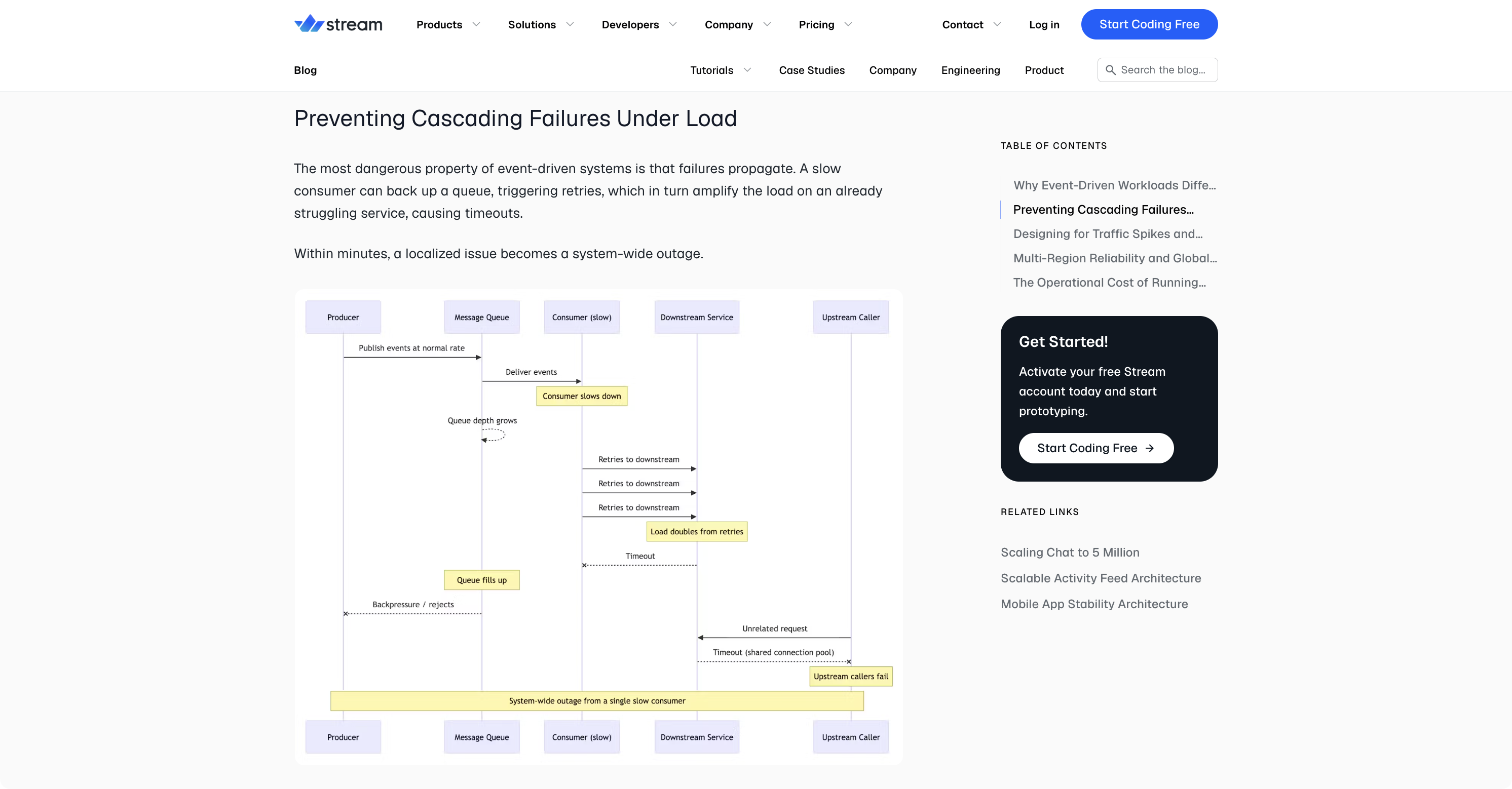
The visuals
Useful when the reader needs to see how pieces connect. The common failure is abstraction: a diagram with five boxes labeled “API,” “Service,” “Database,” “Queue,” and “Client” tells the reader nothing they didn’t already know. Good diagrams show something specific, like the actual flow of a request through a specific system, or the exact failure mode that happens when a specific component goes down.
There are more: cost models and trade-off tables for the CTOs; Error guides and sandboxes for developers; Screenshots and video for the less-technical folk. You should always think of content as a visual medium beyond just words. Not just text, but texture.
What makes technical content marketing work?
You can get the format right, use the right building blocks, and still produce content that devs don’t like.
- Technical content is written by technical writers. You need people who know the subject, or you need to work closely enough with someone who does. Most commodity content marketing agencies fail at technical content because they staff it with generalist writers who are good at structure but can’t tell the difference between a credible claim and a nonsense one.
- Help first, plug later. Lead with the problem, the framework, or the argument. If your product is the answer, great! If not, don’t force it. If you are writing about a problem your developer audience has, then coming to associate you with help means they’ll turn to your product down the line.
- Distribution matters. A piece you want to turn up on search or in an LLM answer is different to a piece you want shared on HN. What is the job the piece is supposed to do? This will inform how you write and what you write about.
- Prioritize the human, the machine will follow. Yes, your content is now read by machines, and yes, it is vital, distribution-wise, that your content shows up in SEO and AEO. This is a real distribution channel now, and it rewards structure, clarity, and machine-readability in ways that will feel familiar to anyone who already writes good reference docs.
How does AI change this?
AI has changed this world. Now, a developer might read your how-to, but they might also just paste the markdown version into Claude Code. When a developer asks Claude or Cursor or Codex to “pick a vector database for this RAG pipeline. Make no mistakes,” the model’s answer depends on what it has seen.
Right now, this doesn’t change anything. Clear headings, explicit trade-offs, stated assumptions, and unambiguous code samples all help a human reader and also help a machine reader work with your content accurately.
Long term, you can see technical content marketing bifurcating into two streams.
1. Reference materials and how-tos for machines
The rote content. The API references, the error code lookups, the step-by-step procedures that an agent reads once and turns into a working implementation. This content will trend toward sparse directness. No throat-clearing, no narrative voice, no “in this guide we’ll explore” preamble. Just the facts, structured so a machine can parse them and a developer can verify them after the fact.
Most of it will probably be machine-generated itself, because the job is pattern-matching and completeness rather than insight. What will matter is that it’s findable and legible to agents: good AEO, clean heading hierarchy, predictable schemas, stable URLs, explicit relationships between concepts. The goal is to be the source an agent reaches for and cites correctly, not the source a human reads for pleasure.
2. Explainers and tutorials for humans
The content on the other side goes the opposite way. It gets more opinionated, more nuanced, and more of an actual read.
Because the rote work is being delegated to agents, the developer’s job is shifting toward instructing those agents well and evaluating what they produce. That requires a deeper conceptual understanding than copy-pasting a how-to ever did. The developer who can tell Claude “use pgvector with cosine similarity and HNSW indexing because our workload is read-heavy and our team doesn’t have the ops capacity for a dedicated vector database” needs to have read an explainer that actually taught them how to think about the trade-off.
That’s the content that earns the developer’s time now: a clear point of view, a real opinion from someone who has been there, and enough depth that the reader walks away better at their job. The standard for this kind of content will get far higher, because the alternative (shallow overviews that a model could have generated) is exactly what developers will have stopped reading.
The agencies and in-house teams that win the next five years are the ones that figure out which of these two streams they’re actually good at, and stop pretending they can do both with the same writers.
All the articles linked in this piece were written or edited by Argot. If you’re interested in working with us, shoot us an email at work@argot.dev